In the first two posts of this series (Part 1, Part 2) we established that red teaming is fundamentally a critical thinking exercise that extends far beyond the narrow technical focus currently dominating AI discourse. We argued that effective red teaming must bring together multifunctional and cross-functional teams to proactively look for novel failure modes in user-facing systems, going back to its origin story to motivate this framing that goes beyond simple adversarial probing.
In this third installment, let’s dive deeper into the question of implementing this holistic view of red teaming across the AI development lifecycle. We propose that AI red teaming be operationalized at two complementary levels: macro-level (or system) red teaming that spans the entire AI development lifecycle, and micro-level (or model) red teaming that focuses on the model powering the AI system.
Macro-level (or System) Red Teaming
Just like technical debt in ML systems can arise from system components other than code1, the figure below shows that ML (and AI) failures can stem from decisions made long before the first line of code is written.
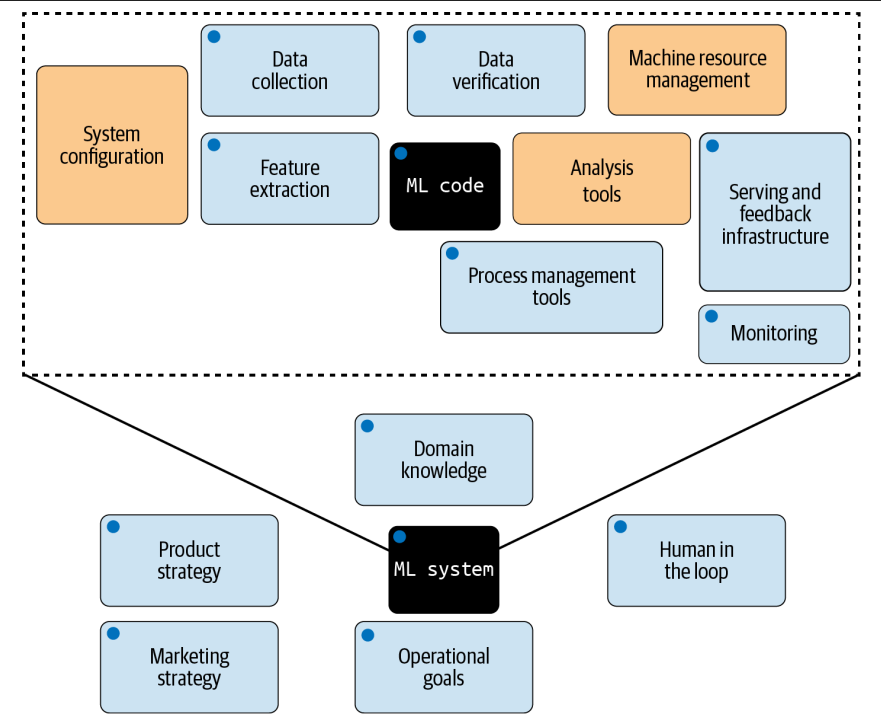 Fig. 1: Technical and nontechnical components of a ML system, with those with potential trust considerations marked by blue circles2.
Fig. 1: Technical and nontechnical components of a ML system, with those with potential trust considerations marked by blue circles2.
In such complex systems, effective risk mitigation requires critical thinking at multiple stages of the process of planning, building and deploying such systems. With this motivation, we break down AI red teaming considerations into seven stages: inception, design, data, development, deployment, maintenance, and retirement. Let’s look into each stage in detail below and what unique red teaming considerations are warranted in each stage.
Inception
The inception stage is critical, given this is where stakeholders first envision an AI solution to address a particular challenge. During this stage, the job of macro-level red teaming is to challenge fundamental assumptions about problem framing and solution appropriateness. Red teams at this stage should ask probing questions: Is AI actually necessary to solve this problem, or are we succumbing to “AI solutionism”? What are the stakeholder motivations driving this project, and how might different constituencies be affected? What adjacent problems might we inadvertently create? How might adversaries exploit or manipulate this system once deployed?3
The red team should also examine the broader ecosystem in which the proposed solution will operate. This includes understanding regulatory landscapes, competitive dynamics, societal contexts, and potential downstream effects. A red team might simulate scenarios where the AI solution succeeds technically but fails commercially, ethically, or socially. They should also consider how the solution might be weaponized, misused, or have unintended consequences at scale.
Critically, they should help everyone be on the same page to answer the question “what does good look like?” To this end, stakeholders need to articulate not just what they want the system to do, but what they absolutely cannot allow it to do. This negative space definition often reveals assumptions and constraints that weren’t initially apparent 4.
Design
The design stage transforms abstract concepts into concrete specifications, wireframes, and architectures. The objective of red teaming during design is to identify systemic vulnerabilities that emerge from interface decisions, architectural choices, and integration points with existing systems.
Red teams should scrutinize the proposed architecture for potential failure modes. How might different components interact in unexpected ways? What happens when the system encounters edge cases or operates outside its intended parameters? How might data flows be corrupted, manipulated, or intercepted? What are the implications of choosing particular algorithms, frameworks, or third-party components?5
Human-AI interaction design deserves particular attention. Red teams should challenge assumptions about user behavior, exploring how people might game the system, develop over-reliance, or use it in ways that compound rather than mitigate risks6. They should also examine how the system communicates uncertainty, handles errors, and maintains user agency.
The design stage is also crucial for establishing monitoring and governance structures. Red teams should ensure that observability, explainability, and control mechanisms are built into the architecture from the beginning rather than retrofitted later. They should challenge whether proposed oversight mechanisms are sufficient, practical, and resilient to various failure modes.
Data
Data is the foundation upon which AI systems are built, yet we often don’t vet and scrutinize the datasets and data pipelines enough, until problems manifest in production. Red teaming during the data stage needs to examine not just data quality but the entire data ecosystem—collection methods, storage practices, access controls, lineage tracking, and lifecycle management.
Red teams should challenge assumptions about data representativeness and quality. Training datasets frequently underrepresent certain populations or edge case scenarios, creating systematic vulnerabilities. Historical biases embedded in data perpetuate and amplify existing inequities, particularly when combined with algorithmic optimization7. Data distribution shifts over time can adversely impact system performance in ways that may not be immediately apparent.
Privacy and security concerns can intersect to create additional vectors of attack. Data de-anonymization techniques continue to evolve, making supposedly anonymous datasets vulnerable to inference attacks. Adversaries can poison training data through strategic injection of malicious samples designed to influence system behavior. Data governance practices often fail to account for aggregated risks of seemingly benign data combinations, while dependencies on external data sources create single points of failure.
Development
Red teaming during the development of an AI system focuses on how implementation choices create systemic vulnerabilities and how development practices themselves introduce risks. Red teams should examine development environment security with particular attention to supply chain risks. Code and model artifacts require robust security and versioning practices to prevent unauthorized modification. Dependency management represents a significant attack vector, as compromised third-party libraries can introduce vulnerabilities throughout the system8. Supply chain attacks targeting development tools can compromise entire development pipelines.
The model training/fine-tuning process introduces risk factors that require systematic evaluation. Hyperparameter choices and optimization procedures can inadvertently introduce biases or create exploitable patterns. Training interruptions or data corruption can degrade model performance in subtle ways that only become apparent after observed failures.
Integration points between AI components and existing systems create complex attack surfaces. Each integration point represents a potential vulnerability where attackers can manipulate inputs, intercept outputs, or exploit protocol weaknesses. Comprehensive integration testing must explore adversarial scenarios and failure modes beyond functional verification.
Deployment
Red teams must scrutinize deployment infrastructure, both during the Inception and Development phases, and identify critical control points for multiple failure modes. Model artifact distribution and update mechanisms can introduce not only security vulnerabilities but also version inconsistencies that degrade system reliability. Deployment failures and rollback procedures require testing for graceful degradation scenarios—systems should maintain partial functionality rather than complete failure when updates fail. The deployment pipeline represents both a security target and a single point of failure that can compromise system availability.
The production environment introduces performance challenges and reliability constraints that differ fundamentally from development conditions. Real-world load patterns can trigger cascading failures, resource exhaustion, and performance bottlenecks that compromise both availability and safety in critical applications. Dependencies on external services create reliability risks requiring circuit breakers and fallback mechanisms to maintain system resilience.
User interaction patterns in production often differ significantly from development assumptions, creating new attack vectors and safety risks9. Real users exhibit behaviors that can expose edge cases leading to incorrect outputs or system failures. The scale and diversity of production usage can reveal reliability issues that only manifest under specific load patterns, while safety-critical applications must account for (benign and adversarial) user behaviors that could lead to harmful outcomes.
Maintenance
Red teams must evaluate monitoring and alerting systems as the first line of defense against diverse failure modes. Many organizations track basic technical metrics but fail to monitor for gradual performance degradation, bias drift, or safety-relevant behavioral changes that may indicate systemic problems. Anomaly detection systems often generate false positives leading to alert fatigue, potentially masking genuine security incidents, reliability issues, or safety concerns. Comprehensive monitoring requires tracking output quality trends, fairness metrics, and safety-critical performance indicators.
Model drift is a fundamental threat to system reliability and safety beyond security concerns10. AI system performance typically degrades over time as real-world conditions diverge from training assumptions, potentially leading to incorrect decisions in safety-critical contexts. This degradation can manifest as gradual accuracy loss, increased (statistical) bias and variance, or failures in edge cases that compromise reliability, security, and safety. The decision of when to retrain models also involves balancing multiple risks: maintaining degraded performance, introducing new failure modes through updates, and ensuring continuity of service.
Risks created by organization-specific operational practices evolve with organizational maturity. Incident response procedures designed for traditional IT systems may be inadequate for AI-specific failures that require domain expertise to diagnose whether problems are security-related, reliability issues, or safety concerns. System changes often lack comprehensive testing for all failure modes, creating opportunities for introducing reliability issues or safety hazards alongside security vulnerabilities.
Retirement
Eventually, all AI systems reach the end of their useful life and must be retired. Red teams must examine data retention and destruction practices as critical considerations extending beyond security. Data stores containing training data and operational logs create ongoing privacy risks, but also represent valuable assets for understanding system behavior patterns and failure modes that inform future safety and reliability improvements. Secure data destruction must balance legal retention requirements with the need to preserve lessons learned about system performance, safety incidents, and reliability patterns. Residual data in backups can expose not only sensitive information but also valuable insights about system failure modes.
The process of migrating users to alternative systems introduces a number of transitional risks. User notification processes must account for potential confusion that could lead to safety incidents if users interact with incorrect systems or experience service gaps. System dependencies often extend beyond obvious integrations to include safety-critical workflows, reliability assumptions, and operational procedures that may fail when the underlying system is removed. Successor systems must account for the full range of use cases and failure handling that the retiring system provided.
Concerns due to legacy risks persist for a while after retirement. Based on the utility of the old system, organizational memory may retain outdated assumptions about system capabilities, leading to safety incidents or reliability problems in successor systems. Documentation of failure modes, safety incidents, and reliability patterns from the retired system provides valuable insights for future development while requiring careful handling to avoid disclosing sensitive information. The institutional knowledge about how to recognize and respond to specific types of failures may be lost with system retirement, creating blind spots in organizational resilience.
Micro-level (Model) Red Teaming
Inie et al11 proposed a grounded theory of LLM red teaming—based on interviews with a diverse group of AI and security practitioners—in a recent paper. We follow them to summarize best practices for red teaming the generative models underlying AI systems.
Fundamentally, the goals of model red teaming are three-fold.
- Boundary seeking to identify the limits of model capabilities,
- Generating content that reveals unexpected capabilities or limitations, and
- Discovering risks inherent to the models before they manifest in real-world deployments.
To achieve these goals, Inie et al. developed a taxonomy of 12 strategies and 35 techniques, organized into five categories that combine technical knowledge with creative problem-solving. Conceptually, this structure is reminiscent of the Tactics, Techniques and Procedures (TTP) framework in cybersecurity.
Finally, effective model red teaming requires incorporating diverse user perspectives and community voices into the evaluation process4. Red teaming should go beyond system-centric testing to consider how different communities experience AI systems and what constitutes harm from their perspectives. This approach recognizes that AI vulnerabilities often manifest differently across demographic groups and use contexts, making diverse participation essential for comprehensive risk discovery.
Conclusion
Macro-level and micro-level red teaming are complementary approaches that together provide comprehensive coverage of AI system risks. Macro-level insights inform micro-level testing priorities, while micro-level findings inform macro-level risk assessments—technical vulnerabilities have implications for system architecture and operational procedures.
Effective AI red teaming requires both perspectives applied consistently throughout the development lifecycle12. It should ideally be a collaboration that brings together diverse expertise—both technical and non-technical—to challenge assumptions and identify blind spots across stages of the lifecycle13. In our next blog post, we’ll wrap up this series by providing a systems perspective on building AI systems and discussing how red teaming is an indispensable part of this process.
References
Hidden Technical Debt in Machine Learning Systems. Sculley et al. NIPS, 2015. ↩︎
Practicing Trustworthy Machine Learning. Pruksachatkun et al. 2022. ↩︎
The Applied Critical Thinking Handbook, version 7.0. TRADCOC G2, 2015. ↩︎
Red-Teaming in the Public Interest. Singh et al, 2025. ↩︎
What is red teaming? Anderson, Holdsworth, and Kosinski, 2025. ↩︎
Challenges in red teaming AI systems. Anthropic, 2024. ↩︎
3 takeaways from red teaming 100 generative AI products. Microsoft Security Team. Microsoft Security Blog, 2025. ↩︎
Defining LLM Red Teaming. NVIDIA Technical Blog, 2025. ↩︎
Revisiting AI Red-Teaming. Ji and Shea-Blymyer, 2024. ↩︎
Agentic AI Red Teaming Guide. Cloud Security Alliance, 2024. ↩︎
Summon a demon and bind it: A grounded theory of LLM red teaming. Inie et al, PLOS One, 2025. ↩︎
Red Teaming Handbook, 3rd Edition. UK Government. Development, Concepts and Doctrine Centre, 2021. ↩︎
Red Team: How to Succeed By Thinking Like the Enemy. Zenko, 2015. ↩︎